
Suksesi i ChatGPT dhe aplikacioneve tjera inteligjente ka krijuar te publiku përshtypjen se tani obligimet e njeriut do të lehtësohen tejmase dhe në të ardhmen gjithçka do jetë automatike, pa qenë të vetëdijshëm sesa probleme kanë këto programe dhe sa lehtë ato mund të sjellin vendime të gabura. Duke qenë se inteligjenca artificiale padyshim do të mbetet pjesë e përditshmërisë tonë, është e rëndësishme të jemi të informuar për të mirat e saj por edhe e përgatitur për rreziqet që ajo sjell, shkruan Portalb.mk.
Rastet e keqfunksionimit të programeve inteligjente janë shpeshtuar dhe viteve të fundit, në kuadër të BE-së dhe Këshillit Evropian, janë miratuar një numër i madh dokumentesh dhe propozimesh për të rritur ndërgjegjësimin për kërcënimin që paraqesin këto produkte teknologjike ndaj të drejtave të njeriut.
Në një hulumtim nga Dr. Igor Kambovski dhe Mr. Elena Stojanovska për efektin e teknologjive të reja, me fokus të veçantë mbi inteligjencën artificiale, thuhet se përdorimi i saj në vendimmarje sjell rrezik serioz për të qenë diskriminues, sidomos kur marrim parasysh faktin se nuk mund të arsyetohet sesi një program inteligjent ka ardhur në një përfundim të caktuar.
“Për shembull, përdoruesit e shërbimeve të bankës shpesh nuk kanë informacion se vendimet për kërkesat e tyre për kredi merren nga sistemet e inteligjencës artificiale dhe jo nga njerëzit. Së dyti, përdoruesit e shërbimeve të bankës, edhe kur e dinë se kërkesat e tyre vendosen nga një sistem inteligjence artificiale, nuk kanë shpjegim të duhur pse kërkesa e tyre u refuzua, kështu që është logjike që klientët vështirë të përcaktojnë nëse vendimi algoritmik është diskriminues apo jo”, thuhet në hulumtim.
Një diskutim i ngjashëm u mbajt vitin e kaluar në Shkup, me përfaqësues nga FIZhT, Shoqata e Teknologjisë dhe Internetit të Rumanisë, Partnerët për Ndryshim Demokratik Serbi dhe Iniciativa evropiane për të drejtat digjitale nga Belgjika, ku u numëruan disa nga rastet më fatkeqe të keqfunksionimit të programeve inteligjente.
“Të mos e harrojmë skandalin që ndodhi në Holandë me asistencën sociale, e që ishte një sistem shumë i thjeshtë i inteligjencës artificiale. Sistemi tregoi se ka njerëz që gënjejnë gjatë parashtrimit të kërkesës për ndihmë sociale. Ky sistem i inteligjencës artificiale analizonte gjëra të tilla si vendbanimi, përkatësia etnike, etj. Si pasojë e funksionimit të këtij sistemi, disa personave pa të drejtë iu është hequr e drejta për ndihmë sociale, disa të tjerëve iu morën fëmijët, disa madje edhe u vetëvranë”, tha Ella Jakubovska, këshilltare e lartë për politika pranë Iniciativës Evropiane për të Drejtat Digjitale nga Belgjika.
Natyrisht që edhe vendet e Ballkanit e kanë hetuar popullaritetin e produkteve të inteligjencës artificiale, e njëkohësisht edhe rritjen e rrezikut nga përdorimi i tyre. Maqedonia e Veriut në vitin 2021 formoi një grup punues që do të krijonte një Strategji Kombëtare për IA, për të ndihmuar personat që duan ta njohin inteligjencën artificiale dhe të merren me të. Në kuadër të kësaj strategjie shumë kompanive fillestare vendase do u jepet mundësi për të realizuar idetë dhe projektet e tyre me trajnimin e duhur si dhe qasje në pajisje moderne. Në grupin punues bëjnë pjesë përfaqësues të kompanisë Aspiegel, Web Factory, Masit, Pixel, Ministrisë së Ekonomisë, Shoqatës Konekt, Fondacionit Metamorfozis, Fakultetit të Inxhinierisë Elektrike dhe Teknologjisë Informatike si dhe Ministrisë së Shoqërisë Informatike.
Pse është vështirë të krijohet një program inteligjent që nuk diskriminon?
Përkundër teorive të ndryshme që përhapen në opinionin e gjerë publik, zhvilluesit e IA-së nuk i “kurdisin” qëllimisht programet inteligjente që të funksionojnë në dëm të shoqërisë, e as nuk i mbajnë nën kontroll ato për shkak se përndryshe do të përgatisin komplot kundër njerëzimit. E vërteta është se logjika e një programi inteligjent nuk “shkruhet”, nuk ka rreshta të kodit që thonë “nëse X është shqiptar, injoroje”. Pjesa më e madhe e punës qëndron në mënyrën sesi përgatiten të dhënat.
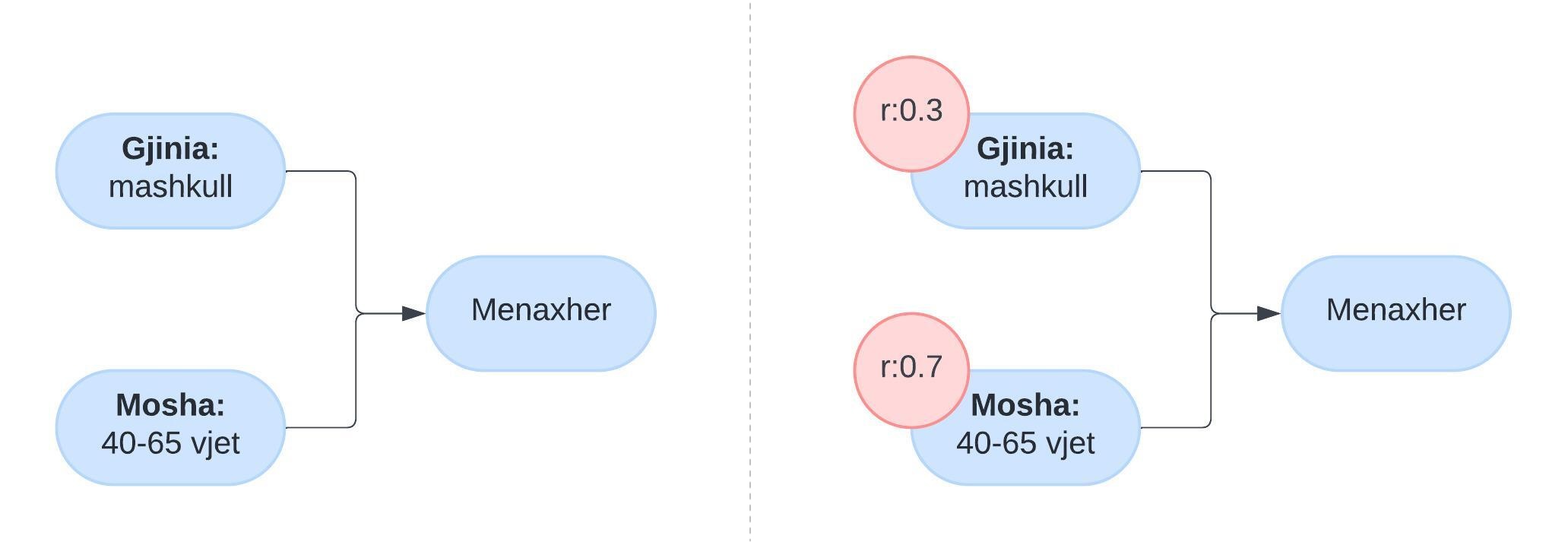
Në qoftë se duam të trajnojmë një program inteligjent që bën përzgjedhjen e punonjësve të ardhshëm të një kompanie, në skenarin më të thjeshtë, do na duheshin mjaftueshëm të dhëna për të krijuar të paktën një tabelë statistikore (70% e menaxherëve janë mbi 30 vjet, 13.7% janë nga Evropa, 23% janë flokverdhë…) dhe t’ia ofrojmë atë IA-së. Kjo tabelë krijohet pasi mblidhen të dhënat nga, p.sh. CV-të e 10 000 punonjësve dhe i mundëson IA-së të “mësojë” relacione siç janë psh: Nëse kandidati është mbi 30 vjet, është i përshtatshëm për t’u bërë menaxher.
Pengesat e para që shfaqen në një situatë të tillë, janë paragjykimet që veçse i ka shoqëria dhe natyrisht, pasqyrohen tek të dhënat. Për shembull nëse në tabela vetëm 14% e menaxherëve janë gra, atëherë IA do të paragjykojë gratë si jo të përshtatshme për rol menaxherial dhe paragjykimet e tilla janë vështirë për t’u eleminuar, meqë nuk mund të krijojmë tabela të rrejshme.
Kështu, një mënyrë se si zhvilluesit e IA-së përballen me këto probleme është duke u bashkangjitur një indikator rëndësie çdo faktori. Për rastin tonë hipotetik, mes moshës dhe gjinisë, mund “t’ia bëjmë me dije” IA-së t’i kushtojë më shumë rëndësi moshës, sepse indikatori i saj i rëndësisë është më i lartë.
Mirëpo në një rrjet neural ka miliona faktorësh të këtillë, që ndërlidhen njëri me tjetrin.
A mund të parashikojmë si do të ndikojë njëri prej tyre, ose indikatori i njërit prej tyre në rezultatin përfundimtar?
“Efekti i fluturës” që krijon një rrjet neural është pengesa e dytë që kushtëzon dhe ndërlikon zhvillimin e një aplikacioni inteligjent efektiv.
Edhe për zhvilluesit e IA, procesi i mësimit artificial është rastësor
Ajo që realisht ndodh kur trajnohet një program inteligjent, është se në mënyrë rastësore ndërrohen disa indikator rëndësie, ose injorohen disa faktor. Domethënë, rastësisht mund të injorohet mosha, ose të ulet indikatori i rëndësisë së saj dhe pas çdo konfigurimi të rastësishëm testohet se a funksionon mirë programi inteligjent, e që nënkupton se, jo, zhvilluesit e saj nuk e kanë nën kontroll dhe nuk mund ta parashikojnë se çfarë do të mësojë një program inteligjent.
Nga të dhënat që duhen për ta trajnuar një IA, një pjesë ndahet për ta testuar se çfarë ka mësuar ajo dhe këtu shihet se sa është funksionale, mirëpo, kjo përsëri nuk do të thotë se programi është gati për në treg. Një IA kërkon ngjashmëri dhe dallime në të dhënat, por nuk mund të parashikohet se çfarë ngjashmëri dhe dallime do të gjejë. P.sh. nga një numër i madh aplikimesh ajo mund të mësojë se shumica e aplikantëve që janë menaxherë të suksesshëm e kanë filluar përshkrimin e tyre me fjalët “Unë jam” dhe si pasojë ta vlerësojë çdo aplikant që e ka filluar kështu CV-në si goxha të përshtatshëm. Nga fotografitë e avokatëve të kompanisë, mund të mësojë jo tiparet e fytyrës, por nivelin e dritës, ose nivelin e kontrastit, ose gjatësinë e flokëve. Prandaj, shumë programe inteligjente mund të jenë 100% efektive në vendimmarje me të dhënat e përgatitura për të, por gjithsesi dështojnë në treg.
Jashari: Sfida nuk qëndron te sistemet e IA, por te vet njerëzit

Bardhyl Jashari, udhëheqës i Fondacionit Metamorfozis dhe njëkohësisht pjesë e grupit punues të Strategjisë Kombëtare të IA, deklaroi se baza e të dhënave me të cilat mëson programi është shumë më e rëndësishme se modeli i mësimit. Të dhënat, sipas tij, janë themeli mbi të cilin ndërtohen sistemet e IA, dhe drejtpërdrejt ndikojnë dhe formësojnë aftësitë dhe rezultatet e këtyre sistemeve.
“Paramendoni një shtëpi: mundeni të keni një arkitekt të shkëlqyer dhe një ekip të aftë ndërtimi, por nëse themeli është i dobët, e gjithë struktura është në rrezik. Cilësia e të dhënave luan një rol të ngjashëm – edhe algoritmet më të sofistikuara të IA nuk do të kishin mund t’i tejkalojnë mangësitë e të dhënave të mangëta”, thotë Jashari.
Jashari shtoi se interneti është përplot përmbajtje diskriminuese, paragjykime dhe urrejtje, e nëse gjatë dizajnimit të programeve që përdorin IA, lejojmë që pa kontroll, sistemi i IA të mësoj nga këto të dhëna, do të kemi rezultate problematike. Prandaj, të dhënat e përdorura për ta trajnuar apo mësuar sistemin e bazuar në IA duhet të jenë gjithëpërfshirëse dhe të paanshme.
Sipas tij, kjo mund të bëhet duke mbledhur të dhëna nga burime të ndryshme dhe përdorimin e teknikave për të zbuluar dhe hequr paragjykimet brenda bashkësisë së të dhënave të përdorura. Pastaj, vetë algoritmet e IA mund të modifikohen për të qenë më të drejtë dhe të mënjanojnë paragjykimet diskriminuese në procesin e vendimmarrjes.
“Në këtë proces, transparenca është vendimtare. Duke i bërë sistemet e IA më transparente, mundësohet shqyrtimi dhe identifikimi i paragjykimeve të mundshme. Revizionet dhe kontrollet e rregullta mund të ndihmojnë në identifikimin dhe adresimin e çështjeve diskriminuese në sistemet e IA përpara se ata të shkaktojnë dëm”, thotë ai.
Jashari i vuri theks faktit se IA-ja nuk duhet tërësisht ta zëvendësoje gjykimin dhe vlerësimin njerëzor, veçanërisht për tema të ndjeshme. Mirëpo, sipas tij, edhe gjykimi njerëzor nuk është gjithmonë i pastër nga paragjykimet, që e bën këtë një mision të vështirë, por jo të pamundur.
“Sfida nuk qëndron te sistemet e inteligjencës artificiale”, tha Jashari, “por te vet njerëzit me paragjykimet dhe vlerat e tyre”.
Link deri tek origjinali: Inteligjenca artificiale mund të diskriminojë: Pse ende nuk është efektive në vendimmarrje? – Portalb







